II. FABRICACIÓN DE LAS PARTES: DEL ADN A LAS PROTEÍNAS
COMO vimos anteriormente, la escalera que forma a la molécula del ADN puede abrirse longitudinalmente al separarse las mitades de los escalones temporalmente por rompimiento de los puentes de hidrógeno que mantienen unidas a las bases complementarias. Cada mitad de escalón, desconectada, puede entonces asociarse a una contraparte provisional, formando así un nuevo par de bases. La cadena de bases sintetizada sobre el molde del ADN es necesariamente complementaria al segmento abierto de la escalera. A medida que la molécula del ADN se abre y la información se transmite, se va formando una nueva molécula complementaria. La cadena sintetizada será de ADN cuando el ADN se duplica, mientras que cuando la información del ADN se pasa a una molécula de ácido ribonucleico (ARN) decimos que el código ha sido transcrito.
SÍNTESIS DE LOS ARNs: FABRICACIÓN DE MOLÉCULAS INTERMEDIARIAS
Los ARNs fueron hallados primeramente en las células formando
las estructuras llamadas ribosomas que participan en la síntesis de proteínas.
Años después se descubrieron los ARNs de transferencia (ARNt)
y los ARNs mensajeros (ARNm). En los últimos años
se ha identificado un gran número de ARNs pequeños dentro del núcleo
de las células (ARNsn). A diferencia del ADN, cada
molécula del ARN está formada por una sola cadena de bases, esto
es, como si fuera sólo media escalera y por lo tanto no tiene estructura de
doble hélice. Tres de las bases son idénticas a las del ADN (A,
G, C,), y el uracilo (U) sustituye a la timina apareándose
perfectamente con la adenina. Las bases en las moléculas de los ARNs
contienen además un azúcar diferente al que se encuentra en el ADN.
Los nucleótidos se asocian al azúcar llamado ribosa, mientras que en el ADN
se asocian a la desoxirribosa, cuyas uniones entre los átomos de carbono son
mas estables. Por esta característica los ARNs son más lábiles,
es decir, se rompen con facilidad. Los diferentes tipos de ARNs
varían de tamaño. Hay ARNs muy grandes, como los ribosomales, que
pueden tener miles de nucleótidos y ARNs pequeños con solamente
25-30 nucleótidos. Cada uno de ellos tiene una función diferente en las células,
aunque todas ellas están relacionadas con la transmisión de la información genética.
Participan en la edición de los mensajes, ya sea que ellos mismos lleven el
mensaje, o se encarguen de dirigir el ensamblaje de las proteínas seleccionando
a los componentes de éstas y llevándolos a la línea de ensamble. Tenemos así
que las moléculas de ARN mensajero (Figura II.1) llevan las instrucciones
del ADN a ribosomas que son la línea de ensamble. Ahí, el mensaje
se descifra para. tener las instrucciones y acomodar las partes que forman urna
proteína específica. En este nivel se requiere la ayuda de los" ARN
de transferencia (Figura. II.2), cuyo papel es llevar los aminoacidos, que son
los componentes de una proteína, al sitio de ensamble.
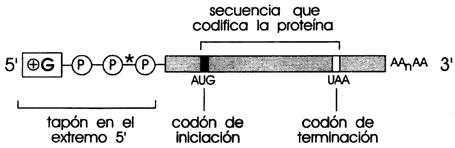
Figura II.1. Estructura del ARN mensajero.
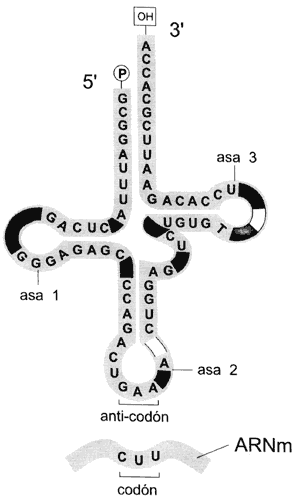
Figura II.2. Asas y regiones de doble cadena en los ARN de
transferencia (ARNt). La región variable en los diferentes ARNt
corresponde al anticodón, donde se une al codón correspondiente en el ARN
mensajero. El extremo 3ñ es al que se unen los aminoácidos.
Los ribosomas mismos están constituidos por ARN ribosomales (Figura
II.3). Cada ribosoma está formado por tres moléculas de ARN, que
en este caso tienen un papel estructural. Los ARNs que son de tamaño
muy pequeño (ARNsn) tienen una participación importante en la edición
de los mensajes, es decir, participan en la modificación del ADN
mensajero, para asegurar que cuando éste llegue a los ribosomas lleve un mensaje
correcto.
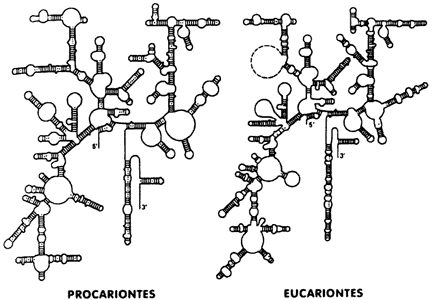
Figura III.3. El complejo arreglo de asas y regiones de doble cadena que
muestran las ARN ribosomales en procariontes (16S) y en eucariontes
(18S). Se nota una cierta similitud estructural entre los ARN,
la cual se mantiene en toda la escala evolutiva.
El tener un material primario o precursor que puede ser arreglado en diferentes formas por corte y reunión de fragmentos de las moléculas de ARN, ofrece un gran número de posibilidades para hacer: 1) diferentes mensajes a partir de una información limitada, y 2) corrección de errores que no se hubieran detectado en la transcripción primaria. Por otro lado, al estudiarse estos procesos quedó claro para los investigadores que estas modificaciones de los ARNs, que implican actividades enzimáticas inherentes a las mismas moléculas, podrían explicar cómo se originó la clave de la información genética y los mecanismos para preservarla y transmitirla. Si consideramos al ARN como el primer biopolímero, o sea, la primera macromolécula biológica que se formó en la tierra primitiva, sus características de enzima le habrían permitido romper y reunir diferentes fragmentos de sí misma, proceso llamado autocatálisis, hasta formar fragmentos con información coherente y por lo tanto utilizable. Una vez formados los fragmentos podrían dar instrucciones para fabricar proteínas. Más tarde, a partir de estos mismos ARNs, se originarían moléculas del ADN, ya que las bases de los dos tipos de moléculas son siempre complementarias. Este paso habría requerido de la reacción inversa a la reacción conocida como transcripción y de la cual ya hemos hablado. De hecho se ha probado que se presenta esta reacción y es mediada por la enzima transcriptasa reversa, que ya ha sido identificada por varios investigadores en todas las células. El ADN como tal, por sus características de estabilidad y capacidad de autorreplicación, sería seleccionado como el almacén de la información genética primeramente organizada al azar por las moléculas primitivas de ARN. Desde ese momento el flujo de información sería de ADN a ARN y se origina la fabricación de proteínas.
La transcripción del ADN para formar una molécula de ARN
se hace por las enzimas llamadas polimerasas del ARN, que incorporan
ribonucleótidos en una cadena leyendo siempre la información que está en el
ADN en la dirección 3ñ-5ñ (Figura II.4). Las diferentes polimerasas
se encargan de sintetizar los distintos tipos de ARNs por un mecanismo
idéntico. Cada polimerasa empieza a leer un mensaje en el ADN cuando
encuentra una señal que le indica dónde y qué tan rápido debe leerlo. Esta señal
puede ser una secuencia especial de bases o la presencia de proteínas reguladoras
en el sitio en donde se inicia la lectura. Una vez iniciada la lectura la polimerasa
continúa incorporando ribonucleótidos a la cadena nueva hasta que se encuentra
una señal en el ADN que le indica que ahí acaba la lectura de ese
mensaje. Este mensaje o transcrito primario se desprende del ADN
y de la polimerasa, y queda libre para ser modificado o llevado directamente
a los ribosomas. El ADN puede volver a cerrar sus medios escalones
en la región de la molécula que fue transcrita.
Si el transcrito tiene información para hacer proteínas es un precursor de
ARN mensajero. El transcrito puede ser también precursor de ARNs
ribosomales, de ARNs de transferencia o de ARNs pequeños.
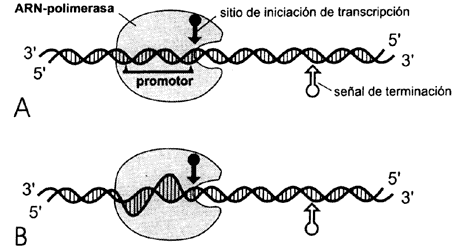
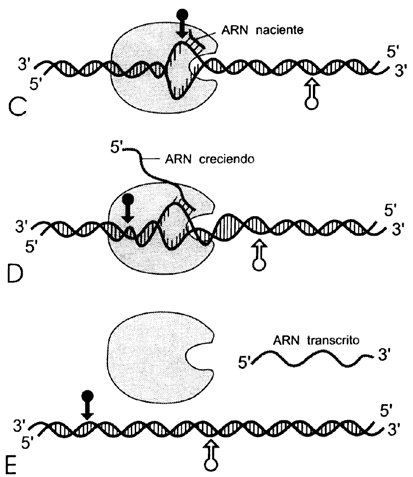
Figura II.4. Esquema de la transcripción: A) Llegada de la ARN-
polimerasa a su promotor; B) desdoblamiento de la doble hélice para que se inicie
la síntesis de ARN; C) iniciación de la síntesis de ARN;
D) alargamiento del ARN a medida que se desplaza la polimerasa;
E) el ARN transcrito se desprende ya completo, al igual que la
polimerasa.
El primer nivel de control de la traducción de un mensaje viene desde la modificación
adecuada del mensaje que va a salir del núcleo a través del proceso de edición,
en un segundo paso ese mensaje se traducirá siempre y cuando tenga las características
esenciales. Por ejemplo, para el primer nivel un ARNm se puede
transcribir en todas las células de un organismo; sin embargo, sólo es editado
adecuadamente en algunas de ellas, permitiendo que la proteína correspondiente
se sintetice solamente en algunas células. Para el segundo nivel de control
se puede usar como ejemplo la presencia y longitud de una secuencia localizada
en el extremo 3ñ de la mayoría de los ARNm, como se ve en la figura
II.1. Esta secuencia de alrededor de 200 bases está formada exclusivamente de
adeninas, por lo que se le conoce como el extremo poli A. La longitud de este
poli A determina la velocidad y frecuencia de traducción de un ARNm,
de modo que ARNs mensajeros con un poli A muy pequeño ya no se
asocian con ribosomas para sintetizar proteínas, de donde se ha propuesto que
la célula no utiliza mensajeros viejos que podrían estar alterados o dañados.
El precursor de un ARNm tiene además bloqueado su extremo 5ñ por
una guanina que se coloca en posición invertida en la cadena de ribonucleótidos,
formando un tapón (Figura II.5), por lo cual no puede ser desprendida por las
enzimas que romperían, un enlace fosfodiéster típico. Este bloqueo se conserva
para proteger a la molécula de ARNm durante el proceso de edición,
al igual que la secuencia poli A mencionada anteriormente. Otras secuencias
que se conservan en el ARNm modificado, esto es, aquellas que codifican
a la proteína respectiva, se llaman exones. Las secuencias que se eliminan durante
la modificación se llaman intrones.
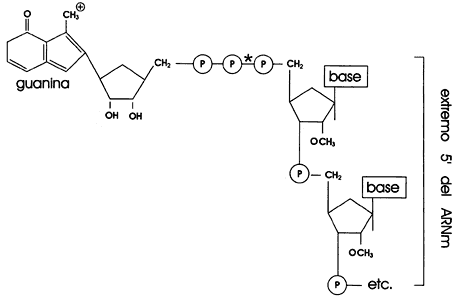
Figura II.5. Bases metiladas en el tapón o casquete del extremo 5ñde los
ARN mensajeros.
Un transcrito primario puede entonces tener varios exones y varios intrones.
Por ejemplo; el gen de ovalbumina, una proteína formada por aproximadaniente
4 300 aminoácidos, contiene las secuencias de siete intrones que se transcriben
al ARNm y se eliminan cuando el ARNm se modifica.
El ARNm que se encuentra en los ribosomas sólo tiene las secuencias
que codifican 4 300 aminoácidos que forman la proteína. Se ha especulado que
los intrones, al no tener un mensaje, son los sitios en que pueden introducirse;
alteraciones (en donde la frecuencia de mutación es muy alta) y aun preservar
sin cambio aquellas secuencias que tienen mensajes que no pueden alterarse para
el funcionamiento normal de las células. La modificación de los ARNm
por remoción de intrones se conoce como splicing que en español correspondería
a edición (Figura II.6). En este proceso participan los ARNsn formando
partículas ribonucleo-proteicas sobre las que se hace la edición. La edición
del mensaje se hace eliminando partes que no se necesitarán para entender las
instrucciones y construir una determinada pieza o proteína o reuniendo fragmentos
de mensajes provenientes de diferentes regiones del ADN y que al
unirse adquieren sentido. Este último proceso de edición seria el equivalente
a formar un párrafo recortando y pegando palabras de varios artículos diferentes
de una revista. Los ARNs ribosomales y los ARNs de
transferencia se sintetizan también de precursores que se transcriben de regiones
especiales del ADN utilizando polimerasas que reconocen las señales
específicas para que estas moléculasfpuedan sintetizarse. Se transcriben como
precursores y deben ser modificados mediante edición de los transcritos primarios
para que puedan convertirse en moléculas funcionales. Estos ARNs
así como los ARNs pequeños no tienen información para hacer proteínas
y participan en los diferentes mecanismos que resultan en la transcripción de
la información de un gen y en la síntesis de las proteínas.
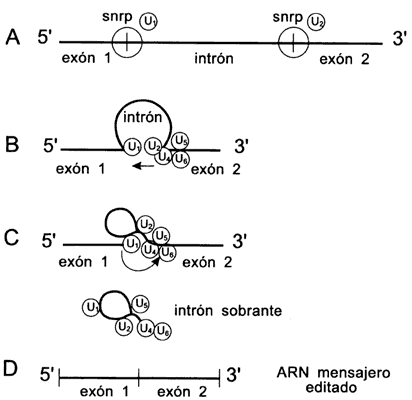
Figura II.6. Proceso de edición (splicing) de un ARN
mensajero snrp = partículas ribonucleoproteicas. Los números 1 a 6 se refieren
a diferentes tipos de partículas: A) mensajero que se va a editar; B) eliminación
del intrón; C) formación de la estructura de lazada (lariat); D) mensajero
editado.
PRODUCCIÓN DE LAS PARTES: SÍNTESIS DE PROTEÍNAS
Las proteínas corresponden a las partes de las diferentes maquinarias celulares
que ejecutan las instrucciones almacenadas en el ADN. Las instrucciones
no se limitan a cómo unir a los aminoácidos sino que también indican cuándo
se traduce el mensaje del cual se construye una proteína y el orden en que ésta
debe construirse. Las instrucciones también permiten que se puedan hacer muchas
copias de una proteína cuando así se requiera. Cada secuencia de tres nucleótidos
en un ARNm forma un codón, es decir, la unidad mínima en la clave
que, al descifrarse, indica qué aminoácido se selecciona para ponerlo en la
línea de ensamble. Un ARNm debe ser por lo tanto tres veces más
largo en nucleótidos que la proteína que codifica.
Cuando un ARNm especifica su información se dice que esta siendo
traducido, pues ése es el momento en que la información contenida originalmente
en el ADN se interpreta y se puede sintetizar una proteína. Los
ARNs de transferencia son los encargados de seleccionar cada uno
de los aminoácidos, lo reconoce y se une a él a través de su extremo 5ñ. Los
ARNt cargados llegan a los ribosomas, en donde el ARNm
está siendo traducido y translocan al ribosoma el aminoácido necesario para
que la proteína se vaya formando. Cada molécula de ARNt se une
solamente a un tipo de los 20 aminoácidos que se encuentran en el citoplasma
de las células y de cuya combinación resultan las proteínas. En el extremo opuesto,
en donde se une el aminoácido a la molécula de ARNt, hay una estructura
en forma de asa y en ella está la secuencia de tres bases llamada anticodón,
la cual encaja perfectamente con el codón del ARNm ya que le es
complementaria (figura II.3) Al engancharse estas secuencias se asegura que
el aminoácido seleccionado se incorpore en el orden preciso en la secuencia
de la proteína que se está sintetizando. Todo este ensamble coordinado entre
codones, anticodones y formación de enlaces químicos entre aminoácidos para
fabricar una proteína se lleva a cabo sobre los ribosomas (Figura II.7). Las
dos partículas de ribosomas contienen moléculas de ARN combinadas
con proteínas. El ARNr de mayor tamaño (llamado de 26 ó
28S) y uno llamado 5S forman la partícula más grande y el de menor tamaño (16
ó 18S) forma la partícula pequeña. El arreglo estructural de los ribosomas
permite que sobre ellos se acomoden todos los elementos que participan en la
construcción de una proteína. En esta compleja línea de ensamble existen también
diferentes enzimas y factores que inician y terminan la traducción del mensaje,
permiten formar la unión entre los aminoácidos y desprender a la proteína completamente
terminada. Un mensaje puede ser usado muchas veces si la célula requiere de
una gran cantidad de una proteína determinada o puede ser descartado si sólo
requiere que se traduzca una sola vez. Estos pasos son controlados por las necesidades
de producción de las células y de acuerdo con programas bien establecidos, lo
que lleva al buen funcionamiento de un organismo. Las proteínas constituyen
más de la mitad del peso seco de una célula, tienen gran diversidad de tamaños,
arreglos tridimensionales y muy variadas funciones. En el humano hay más de
100 000 proteínas diferentes. Algunas son enzimas o catalizadores de reacciones
químicas dentro de las células, otras tienen actividad lítica para destruir
blancos específicos y componentes extraños a la célula, y otras más forman diversas
estructuras celulares. Los aminoácidos que las forman (20 diferentes) son moléculas
con una estructura básica común, formada por un carbono denominado alfa, al
que se une un grupo carboxilo (COOH), un grupo amino (NH2) y un residuo
de varios carbonos y otros átomos que le dan a cada aminoácido su propia personalidad
química y carga eléctrica.
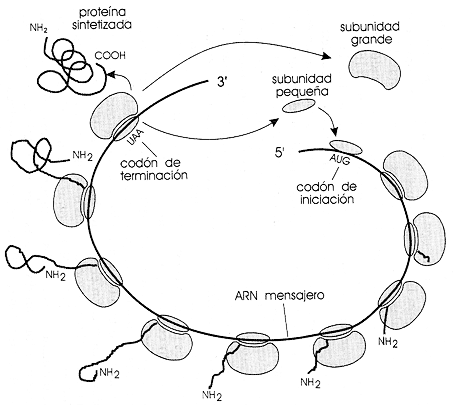
Figura II.7. Traducción de un ARN mensajero y síntesis de la
proteína para la cual lleva la información.
De esta manera se producen aminoácidos básicos, ácidos y neutros, cuya combinación,
al fabricarse una proteína, también le confiere a ésta características químicas
propias. La posibilidad de combinar varios aminoácidos permite también gran
versatilidad en la fabricación de proteínas y por consiguiente en las funciones
que desempeñan. Los diferentes aminoácidos se unen entre sí originándose un
enlace peptídico que se forma entre el grupo carboxilo de un aminoácido y el
grupo amino del aminoácido que se inserta en la cadena. Una cadena o polipéptido
formado de varios aminoácidos tiene entonces un extremo amino terminal y un
extremo carboxilo terminal (Figura II.8). De la secuencia en que se ordenan
los aminoacidos o la estructura primaria de la proteína dependerá la estructura
de ésta a niveles secundarios. Por ejemplo, las interacciones entre ciertos
aminoácidos pueden formar puentes de hidrógeno o puentes disulfuro y dar origen
a regiones en la proteína con forma de espiral o de hojas planas. Las
combinaciones que se dan en estas regiones constituyen lo que se denomina un
dominio. Una proteína pequeña tiene por lo general un dominio, una grande tendrá
varios. Algunas proteínas están constituidas por la asociación de varios polipéptidos
idénticos, otras están formadas por polipéptidos que pueden tener diferente
secuencia de aminoácidos y distinto tamaño. Las proteínas tienen que sintetizarse
con mucha precisión, ya que un solo cambio en un aminoácido es suficiente para
alterar su estructura y función, a veces con resultados fatales. Por ejemplo,
en la proteína hemoglobina, componente principal de los glóbulos rojos de la
sangre, el cambio de glutámico por valina es suficiente para que esta proteína
funcione inadecuadamente y se produzca en el organismo el padecimiento llamado
anemia falciforme.
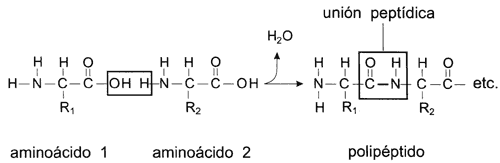
Figura II.8. Formación de la unión peptídica entre aminoácidos para formar
un polipéptido o proteína. Algunas proteínas están formadas por varios polipéptidos
que una vez sintetizados interaccionan entre sí a través de enlaces diversos.
Las proteínas formadas por un solo polipéptido se llaman monoméricas, a diferencia
de las que tienen dos, que son diméricas, tres las triméricas, etc., hasta poliméricas.
En el caso que nos interesa en este libro, que es el de las proteínas que participan en movimiento, éstas se encuentran en el citoplasma de las células formando la matriz fibrosa que constituye el citoesqueleto. Este nombre se deriva de las características estructurales de sus elementos que dan un soporte rígido alrededor del cual se organiza el resto del citoplasma y del cual depende también la forma que adopta la célula y los movimientos que puede realizar. Las primeras observaciones del citoesqueleto en el citoplasma se hicieron desde el siglo XIX. Hay descripciones detalladas de estructuras fibrosas en neuronas, realizadas por Sigmund Freud y Santiago Ramón y Cajal.
Este último, usando técnicas de tinción de plata, pudo describir una matriz organizada en células de glia. No fue sino hasta los años cincuenta y sesenta que el uso del microscopio electrónico y del glutaraldehído, como fijador de células, permitieron la identificación de estructuras individuales y morfológicamente distintas dentro de la matriz citoplásmica. Sin embargo, la verdadera y diversa identidad proteica de los componentes del citoesqueleto se pudo establecer años más tarde, utilizando metodología bioquímica e inmunológica. Analizaremos los componentes proteicos más abundantes del citoesqueleto:
Actina. Ésta es una proteína globular con un peso molecular de 42 700
daltones, es decir, que tiene aproximadamente 427 aminoácidos formando una cadena
lineal o polipéptido. Su nombre deriva del griego y significa rayo. Es una proteína
acídica, pues contiene un elevado porcentaje de aminoácidos ácidos y una carga
eléctrica negativa. Tiene una molécula de Ca2+ asociada que utiliza
la conformación globular y una molécula de ATP, cuyo fosfato terminal
se hidroliza cuando varias moléculas se asocian y polimerizan para formar la
actina filamentosa. Al enredarse dos de estos filamentos se forma un microfilamento
de actina que; se ve al microscopio electrónico como una fibrilla de 7- 9nm
en el citoplasma de las células (Figura II.9).
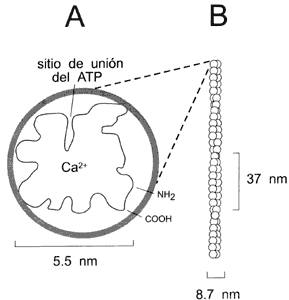
Figura II.9. Estructura de un monómero de actina con sus sitios de unión
a Ca2+ y ATP (A) y de un polímero o microfilamento de
actina (B) formado de muchos monómeros ensamblados en una doble espiral.
Hay varias formas de la actina en los diferentes tipos de células de un organismo y en ocasiones dentro de una misma célula. Las diferencias se deben principalmente a sustituciones de uno o varios aminoácidos que no alteran las propiedades funcionales de la proteína. Así tenemos que la actina alfa es característica del músculo esquelético, mientras que las formas beta y gamma existen en músculo liso y estriado y en células no musculares. Esto significa que en un mismo organismo pueden existir diferentes isoformas de la actina, lo que llevó a considerar que debe haber genes diferentes para codificar a las diferentes actinas. Se ha encontrado que ciertamente existen en una célula varias copias de los genes de la actina, algunas de las cuales se expresan solamente en un tipo celular, por lo que ciertas células sólo fabrican una isoforma de esta proteína —como sería el caso del músculo esquelético—, aunque tienen la información para hacerlas todas. Algunas veces, como en el actinomiceto Dictyostelium discoideum, se expresa una sola forma de la actina, aunque hay 17 copias del gen de ésta.
Una gran variedad de proteínas se asocia a la actina y gobierna de diferentes formas la configuración y función de la proteína y de los microfilamentos. Algunas de estas proteínas regulan, por ejemplo, la viscosidad de la actina purificada formando puentes entre los filamentos, otras forman haces de éstos, provocando rigidez en filamentos en paralelo, algunas forman conexiones a distancia entre las fibras aisladas, y otras mas se unen a filamentos aislados y regulan su polimerización rompiendo el filamento o estabilizándolo. Entre estas proteínas asociadas a la actina se puede citar a la gelsolina, la tropomiosina, la severina, la fimbrina, la vellosina, etc. y, desde luego, la miosina, que junto con la actina puede convertir la energía química del ATP en movimiento contráctil en muchos tipos de células. Hace tiempo se pensaba que la actina y la miosina eran proteínas exclusivas de las células musculares. Ahora se sabe que también son proteínas estructurales en las células no musculares.
Miosina. Es una proteína de gran tamaño. Su nombre se deriva de la voz
músculo ya que es en los tejidos musculares donde se encuentra en gran abundancia.
La etimología de músculo proviene del griego mus (ratón), al parecer
porque los médicos hipocráticos encontraron una analogía entre estos roedores
y las masas de carne que parecen deslizarse rápidamente por debajo de la piel.
La miosina existe en varias formas. La miosina I tiene una cadena de aminoácidos
llamada pesada, porque está formada por 1 200 a 1 400 aminoácidos y una o dos
cadenas ligeras con 130 a 150 aminoácidos. Este tipo de miosinas se encuentra
en células no musculares. La miosina II forma los filamentos gruesos en los
sarcómeros de los músculos y también se encuentra en células no musculares que
requieren la contracción de las estructuras formadas por la actina, como puede
ser el anillo de constricción en una célula en división (Figura II.10). Está
formada por una combinación de seis polipéptidos, dos con cadenas de 2 000 aminoácidos
y dos pares de cadenas ligeras formadas por 160 a 200 aminoácidos. Por su gran
tamaño esta molécula es soluble solamente a altas concentraciones de sal. Cuando
se agregan estos seis polipétidos forman fibras con extremos globulares o cabezas
en donde se acomodan las cadenas ligeras. La combinación de varias de estas
fibras produce un filamento grueso que, visto en el microscopio electrónico,
tiene un diámetro de aproximadamente 30 nm. A diferencia de la actina, las miosinas
varían mucho en su evolución, pero la secuencia de aminoácidos, aunque algo
similar, sí es diferente en los distintos tipos de células. Hay varios genes
para las diferentes miosinas y, como en el caso de la actina, no todos se expresan
en las mismas células. H. Huxley encontró que la parte de la molécula de miosina
que interacciona con la actina se puede desprender del resto de la molécula,
y ya separada puede seguir interaccionando con los filamentos de actina para
formar complejos que, observados al microscopio electrónico, tienen la apariencia
de puntas de flecha. Esta metodología fue utilizada en células no musculares
por H. Ishikawa y sus colaboradores en la Universidad de Pensilvania, quienes
demostraron que los fragmentos de miosina se unían a estructuras específicas
en las células que correspondían en apariencia a los microfilamentos observados
por varios microscopistas en los sarcómeros del músculo. Esta unión es completamente
específica para la actina, lo que permitió no sólo observar en una célula no
muscular a los filamentos de la actina, sino distinguirlos de otros tipos de
estructuras fibrosas en el citoplasma. La interacción de la actina con la miosina
y otras proteínas regula en las células no musculares los movimientos como la
citocinesis y la locomoción, migración de partículas y organillos, contracción
de vacuolas y cambios de forma.
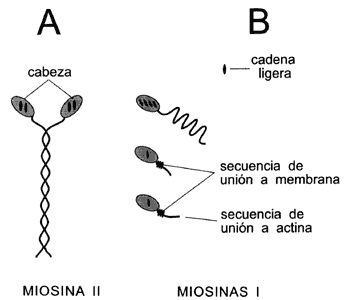
Figura II.10. Diagrama de las moleculas de miosina II (A) y I (B) en el
que se muestra la cabeza globular asociada a las cadenas ligeras.
Tubulina. Esta proteína es también mayoritaria en el citoesqueleto de
las células. Está organizada como un dímero con un peso molecular de 115 000
daltones, en el que participan las proteínas llamadas tubulina alfa y tubulina
beta en la misma proporción (Figura II.11). Cada una de estas proteínas está
formada por aproximadamente 550 aminoácidos, con una buena proporción de residuos
acídicos, por lo que también son proteínas acídicas. Los dos tipos de tubulina,
aunque son similares, no son idénticos y de hecho se transcriben de genes diferentes.
La tubulina alfa puede también estar acetilada, es decir; tener un grupo acetilo
unido a uno de sus aminoácidos. La acetilación ocurre una vez que la proteína
se desprende de los ribosomas. Esta tubulina se comporta en forma diferente
y se asocia en forma particular a estructuras celulares como los flagelos. Se
ha encontrado también tubulina destirosinada, y esto significa que la tubulina
perdió el aminoácido tirosina de su extremo amino terminal, y en esta forma
se le asocia al aparato de Golgi. Las tubulinas son, como la actina, proteínas
conservadas, por lo que su secuencia de aminoácidos no varía mucho en diferentes
células, sean animales o vegetales, y de hecho, si se observan al microscopio
los microtúbulos aislados y las estructuras formadas por microtúbulos, se encuentra
siempre la misma organización básica.
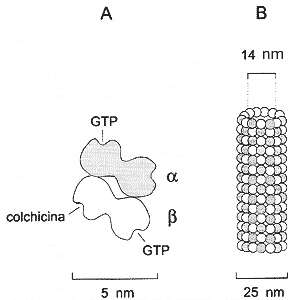
Figura II.11. A) estructura del heterodímero de tubulina con sus sitios
de unión a GTP y a colchicina; B) microtúbulo formado por la polimeración
de los heterodímeros. Un microtúbulo en corte transversal muestra 13 unidades
alrededor de la luz.
Los microtúbulos se ensamblan por la polimerización de los dímeros de tubulina
dejando un espacio central o luz de 10 nm de diámetro, de manera que al cortar
transversalmente un microtúbulo se observan 13 unidades estructurales alrededor
de la luz, correspondientes a los dímeros ordenados para formar el tubo. Recientemente
se ha identificado una tubulina gamma que se encuentra asociada a los centrómeros
de los cromosomas. Hay proteínas asociadas a la tubulina y su papel es facilitar
la polimerización de la proteína en microtúbulos. Estas proteínas forman grupos
llamados MAPS y TAU.
Proteínas de filamentos intermedios. Las proteínas que forman los filamentos
intermedios constituyen el grupo más diverso de proteínas del citoesqueleto;
tienen diferentes propiedades bioquímicas y diferentes tamaños, y contienen
desde 400 hasta 2 000 aminoácidos aunque son codificadas por una familia de
genes similares que se expresan diferencialmente en distintos tipos de células
o en diferentes estadios funcionales. Reciben diferentes nombres, según el tipo
de célula de donde se han aislado. Hay por lo menos 20 subtipos de queratinas
que se han identificado en epitelios, desmina en el músculo, filamentos gliales
en células glia, neurofilamentos en muchos tipos de neurona y vimentina en células
de origen mesenquimatoso. La proteína lámina que forma la membrana de los núcleos
es un miembro de esta familia. Todas estas moléculas tienen una región central
de longitud constante en la que de 30 a 70% de los aminoácidos son idénticos
(Figura II.12). A través de esta región se hace la unión de varias moléculas
para formar el arreglo que finalmente constituye un filamento intermedio. Estos
filamentos son muy estables, por lo que estas proteínas, a diferencia de las
ya mencionadas, no se polimerizan y despolimerizan continuamente. Es frecuente
encontrar fosforiladas a las proteínas de filamentos intermedios, modificación
que es reversible y llevada a cabo por cinasas específicas que responden a señales
celulares relacionadas con niveles iónicos en el citoplasma o con fenómenos
membranales. Se conocen por lo menos dos tipos de proteínas asociadas a filamentos
intermedios: filagrina y sinemina. No obstante, su función específica es poco
clara. En algunas enfermedades, como la de Alzheimer, se ha demostrado que las
proteínas de los filamentos intermedios están alteradas, por lo que muchos investigadores
estudian estas proteínas tratando de establecer una correlación entre esta enfermedad
y la alteración de los filamentos intermedios.
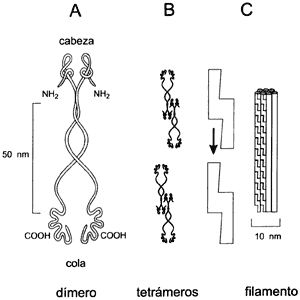
Figura II.12. Interacción de los dímeros de proteínas de filamentos intermedios (A) para formar los tetrámeros (B) que al polimerizar forman la unidad estructural de los filamentos intermedios (C).